2023. 1. 14. 23:54ㆍ파이썬/Python으로 배우는 머신러닝과 데이터분석
1. BoW (Bag of Words) 모델의 이해
BoW 모델은 단어의 순서나 관계를 고려하지 않고,
단어들의 출현 빈도를 이용하여 텍스트 데이터를 수치화하는 표현 방법이다.

위 그림과 같이 bat 2번, can 1번, see 2번과 같이 출현 빈도를 수치화하여 표현하는 방법이다.
2. Word Cloud의 이해

Word Cloud 또는 Tag Cloud는 위 그림과 같이
특정 단어의 출현 빈도수에 따라 단어를 더 크고 선명하게 표현 시켜주는 시각화 방법이다.
3. 프로그래밍
뉴스 데이터를 이용하여 Word Cloud 표현하는 프로그램을 구현할 것이다.
참고로 사용하고 있는 Python의 버전은 3.11.1이다.
아래는 Main 코드인 WordCloudView의 코드이다.
# -*- coding:utf-8 -*-
# 뉴스 데이터 Word Cloud에 필요한 python 패키지를 설치한다.
# pip install konlpy
# pip install pandas
# pip install wordcloud
# pip install KoreaNewsCrawler
# pip install matplotlib
# 뉴스 데이터 분석에 필요한 python 패키지를 로드합니다.
import pandas as pd
import matplotlib.pyplot as plt
from konlpy.tag import Okt
from collections import Counter
from korea_news_crawler.articlecrawler import ArticleCrawler
from wordcloud import WordCloud
from multiprocessing import freeze_support
if __name__ == "__main__" :
#freeze_support()
# 2017년 1월 정치, IT과학, 경제, 생활문화 카테고리 뉴스를 크롤링를 진행한다.
#Crawler = ArticleCrawler()
#Crawler.set_category("정치", "economy")
#Crawler.set_date_range((2017, 1, 2017, 12))
#Crawler.start()
# 형태소 분석 (Morpheme)
# 경제 뉴스를 분석하기 위해 읽어온다.
# pandas의 csv 읽기 기능을 이용하여 파일을 읽어 온다.
# Windows에서 csv 파일을 읽을 때CP949로 encoding을 설정해야 한글이 정상적으로 출력된다.
# 읽어온 경제 뉴스의 칼럼은 id, 날짜, 뉴스 카테고리, 신문사, 제목, 내용, url로 구성되어 있다.
# data = pd.read_csv("Article_economy_201701_201701.csv", encoding='CP949')
data = pd.read_csv("Article_economy_201701_half.csv", encoding = 'utf-8')
# 수집된 데이터에 칼럼명이 존재하지 않으므로 칼럼명을 지정해야 한다.
data.columns = ['cdata', 'category', 'publisher', 'title', 'contents', 'url']
# 지정된 칼럼명을 확인한다.
print(data.columns)
# contents의 내용을 분석해야 하므로 contents의 내용을 읽어서 토큰화한다.
okt = Okt()
tokenized_contents = []
for content in data['contents'] :
temp = []
# 4) 형태소 분석
# Stemming 을 적용하여 토큰화한다.
temp = okt.morphs(content, stem=True)
# 분석 시 의미가 없을 것으로 보이는 단어들을 제거한다.
stopwords = ['의', '가', '이', '은', '를', '는', '을', '좀', '잘', '과', '도', '으로', '하다']
# 토큰화된 데이터를 저장한다.
tokenized_contents.append(temp)
# 추출된 형태소 확인
# 전체 데이터를 확인할 경우 브라우저가 다운될 수 있으므로 첫번째 텍스트만 확인
print(tokenized_contents[0])
# okt.pos 함수를 사용하여 품사를 부착한다.
pos_contents = []
for content in data['contents'] :
pos_temp = okt.pos(content, norm=True, stem=True)
pos_contents.append(pos_temp)
# 명사 추출 확인
pos_contents_noun = []
for item in pos_contents :
for word, pos in item :
if pos == 'Noun' : # 명사만 추출
pos_contents_noun.append(word)
print(pos_contents_noun[0])
# 명사 출현 빈도수 확인
pos_contents = []
for contents in data['contents'] :
nouns = okt.nouns(content)
count = Counter(nouns)
return_contens = []
for n, c in count.most_common(5) : # 5번 이상 반복된 명사만 추출
temp = {'tag':n, 'count':c}
return_contens.append(temp)
# 5번 이상 반복된 명사 추출 확인
print(return_contens)
# Bow(Bag of Word) 추출
word_index = {}
bow = []
for tok_content in tokenized_contents :
for voca in tok_content :
if voca not in word_index.keys() :
word_index[voca] = len(word_index)
bow.insert(len(word_index) - 1, 1)
else :
index = word_index.get(voca)
bow[index] = bow[index] + 1
print(bow)
# 명사 워드 클라우드로 표현하기
str_noun_words = ','.join(pos_contents_noun)
FONT_PATH = 'C:/Windows/Fonts/malgun.ttf' # 윈도우용 한글 For Korean characters
wordcloud = WordCloud(max_font_size=60, background_color='white', font_path=FONT_PATH).generate(str_noun_words)
plt.figure()
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
그리고 서브 코드로 NewsCrawler 코드가 있다.
이는 뉴스 크롤링 자체가 오래 걸리기 때문에
별도의 뉴스 크롤러 파이썬 프로그램이 필요하다.
from korea_news_crawler.articlecrawler import ArticleCrawler
from multiprocessing import freeze_support
if __name__ == '__main__':
freeze_support()
Crawler = ArticleCrawler()
Crawler.set_category("world")
Crawler.set_date_range("2019-01-01","2019-12-31")
Crawler.start()
여기서
1차 문제 발생!
밑에서 2번째 줄에서 오류가 발생했다.
(오류는 깜빡하고 캡쳐하지 못 했다.)
참.. 교육 영상에서 사용한 ArticleCrawler 패키지가 내가 사용한 패키지와 버전이 다르다.
교육 영상이 최신이 아니기 때문에 발생한 문제이다.
마지막 줄에서 2번째인 ("2019-01-01","2019-12-31") 부분은 내가 새로 고친 것이다.
영상은 (2019, 1, 2019, 2)로 되어있다.
이를 어떻게 알았냐?
해당 패키지가 있는 경로로 찾아가
ArticaleCrawler.py 파일을 실행시켜 관련 코드를 찾아보았다.
그 중 set_data_range 메서드 부분으로 가서 관련 형식을 살펴보았다.
def set_date_range(self, start_date:str, end_date:str):
start = list(map(int, start_date.split("-")))
end = list(map(int, end_date.split("-")))
(이 아래에도 무수히 많은 코드가 있지만 이야기하려는 것과 관계없으므로 생략)
위 코드에서 두 번째 줄의 start_data.split("-")은 "-" 문자로 숫자 형식을 구분한다는 것이다.
영상에서 사용된 저 패키지의 내용은 모르나..
나와 달라서 발생한 문제이다.
결과적으로 이런 과정을 통해 해결했다.
2차 문제 발생!
1차 문제를 해결했음에도 문제가 발생했다.
다행히 간단한 문제였다.
이 WordCloud를 프로그래밍하는 데 3시간이나 걸리게 한 주요 원인인
세 번째 문제 발생!
wordcloud 패키지가 다운로드가 안 되는 것이다!
다른 패키지는 모두 설치가 되었는데, 저 패키지 하나만 안 되는 것이다.
그래서
① 첫 번째 해결법 : cmd로 직접 설치하기
https://m.blog.naver.com/nickname_j/222052380491
[Python] wordcloud 설치, (pip install wordcloud error)
wordcloud 를 설치하려고 pip install wordcloud를 입력했더니 시뻘건 에러를 내뱉었다. 이렇게 wordcloud ...
blog.naver.com
위 블로그를 참고해서
wordcloud 패키지를 pycham setting에서가 아닌
cmd에서 직접 설치해봤지만
실패..
과정을 간단히 요약하자면
패키지가 설치되지 않는 이유는
내가 사용하고 있는 파이썬의 버전과 wordcloud 패키지의 버전이 다르기 때문이며,
이를 해결하기 위해
https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud
위 사이트에 들어가서
내 파이썬 버전에 맞는 버전의 패키지를 설치하라는 것이다.
위에서도 언급했지만,
내 파이썬 버전은 3.11.1로
저 사이트에 있는 311 버전을 받아 했다.
cmd에
pip install wordcloud 를 입력해
다운로드를 시도했지만,
뭔 이상한 오류가 발생했다.
Requirement already satisfied: wordcloud in c:~~~[경로]
이미 요청이 완료됐단다..
그런데 해당 경로가서 확인해보면
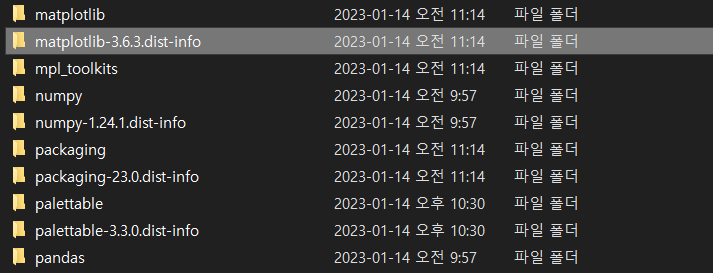
다른 패키지들은 다 폴더가 있는데,
wordcloud 폴더는 수 십번을 확인해도 보이질 않는다.
첫 번째 방법은 실패..
위 문제를 해결하기 위해 여기저기 구글링을 하던 도중
Anaconda prompt를 사용해보라는 글이 있었다.
일반적으로 사용하는 cmd (명령어 프롬프트)와 다를까.. 란 생각으로 시도했는데
cmd와 다른 결과를 냈다.
캡쳐는 못 했지만, Successfully~ 뭐라고 출력되었다.
해당 경로로 찾아가보니,
그렇게 찾아해매던 wordcloud 폴더가 있었다!
지금 생성된것인지, 이전에 있었던 것인지 모르겠지만 있다는 것에 기뻤다!!
그것도 잠시..
이를 복사해서 위 패키지가 모여있는 경로에 붙여놓고,
위 Main 프로그램을 실행했지만...
여전히 문제가 해결되지 않았다.
ModuleNotFoundError: No module named 'wordcloud.query_integral_image'
찾을 수 없는 모듈이란다...
이상한 점은 Main 프로그램에 빨간 글씨로 오류 표시가 없고,
노란 색의 경고 뿐이라는 것이다.
그래서 아까 했던 방법과 같이
패키지의 파이썬 파일을 실행시켜
코드 하나 하나 둘러보았다...만
wordcloud.query_integral_image 메서드는
내 Main 프로그램에 없다
위와 같은 문제는 지금의 역량으론 불가능이다..
내린 결론
결국 원작자의 Github에 방문했다.
https://github.com/amueller/word_cloud
GitHub - amueller/word_cloud: A little word cloud generator in Python
A little word cloud generator in Python. Contribute to amueller/word_cloud development by creating an account on GitHub.
github.com
그리고 여기서 이런 글을 보았다.
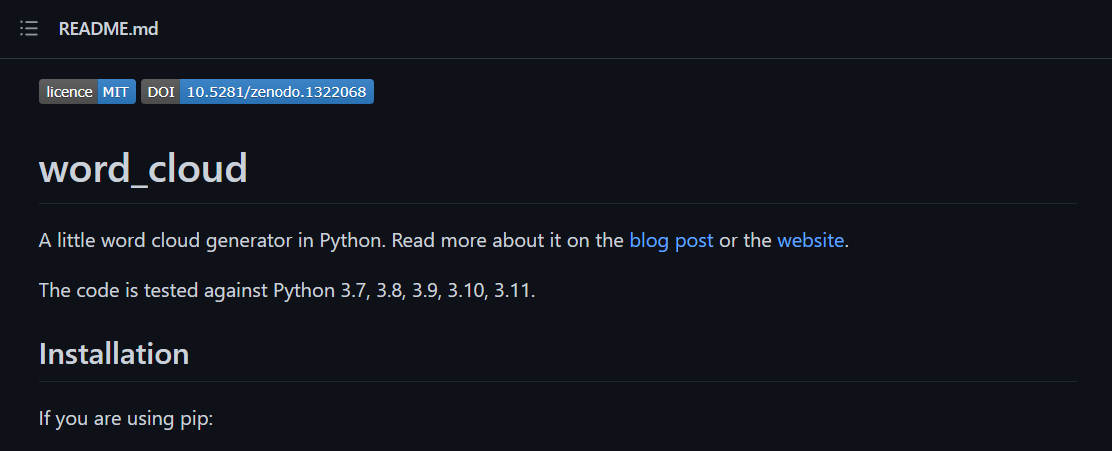
"The code is tested against Python 3.7, 3.8, ... , 3.11."
이란 문장이 보인다.
그래서 내가 내린 결론은
"내 파이썬 버전인 3.11.1에선 아직 호환이 안 되는구나"
이다..
나중에 꼭 wordcloud 프로그래밍 도전해봐야겠다.
'파이썬 > Python으로 배우는 머신러닝과 데이터분석' 카테고리의 다른 글
| 머신러닝 모델 (0) | 2023.01.14 |
|---|---|
| 피처엔지니어링이란? (0) | 2023.01.14 |
| 기초 통계 분석이란? (0) | 2023.01.14 |
| Numpy와 pandas 개요 (0) | 2023.01.14 |